01
Scan ingest
~3 secSonographer uploads the same 3D/4D still she'd hand to the parent. We accept JPG / PNG / MP4 from any modern scanner — GE Voluson, Samsung HERA, Mindray DC-80, Philips EPIQ. No driver, no plugin, no scanner integration.
Inside the pipeline
The Boutique Ultrasound pipeline turns a 3D / 4D ultrasound still into a photoreal newborn portrait the studio can hand to a parent. It's not a generic image-to-image tool — every stage was rebuilt for the specific failure modes of fetal ultrasound data. Here's exactly what happens between upload and delivery.
The full path · upload → delivery
Scan ingest
~3 sec
Vision pipeline
~15 sec
Conditioning + reference embedding
~12 sec
Diffusion rendering
~130 sec
Brand + safety overlay
~12 sec
Gallery delivery
~8 sec
Time distribution
~3 min total
Stage 04 (diffusion rendering) dominates — that's where the actual painting happens. Everything else is sub-15-second infrastructure.
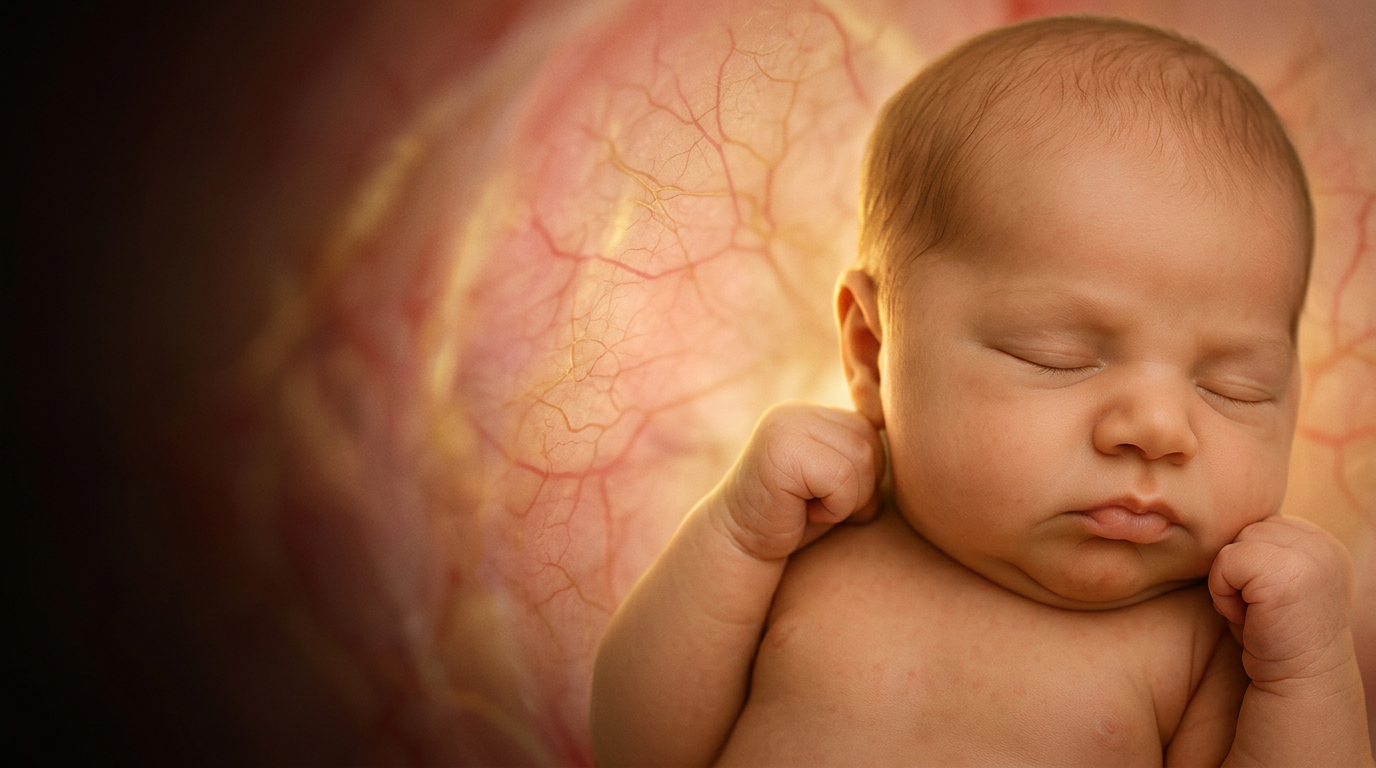
The scan is what the scanner gives you — low effective resolution, grayscale, heavy speckle noise. The portrait is what the model paints from it, conditioned by the structural cues we extract. Same baby, dramatically different image fidelity.
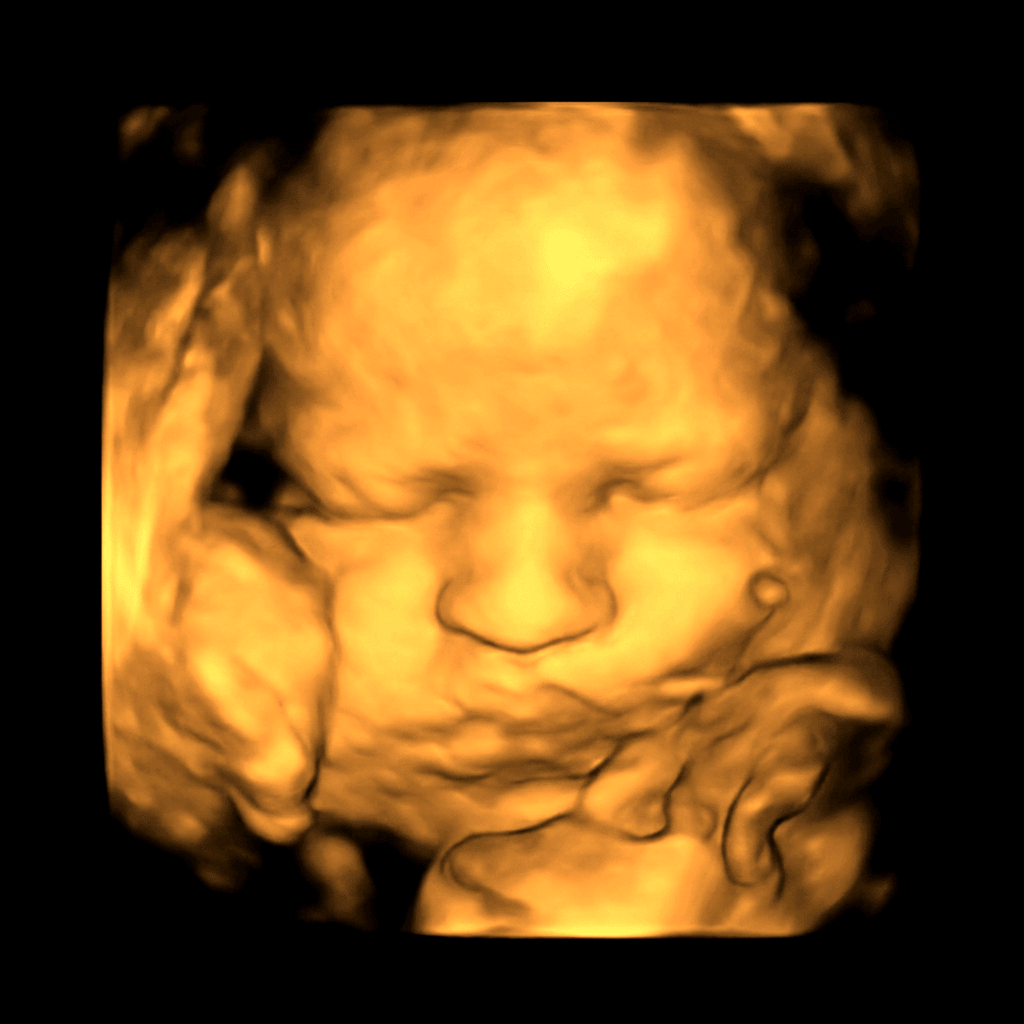
Input · what the scanner gives you
3D ultrasound still
~47× pixel density
structural cues
preserved

Output · what the studio delivers
Photoreal portrait
Artistic interpretation · not a biometric prediction. The model renders in the visual style of a newborn portrait at the pose and proportion the scan dictates.
The vision pipeline finds anchors on the 3D mesh — nose tip, eye orbits, chin curvature, cheek profile — and uses only those signals to constrain the renderer. Anything blurry or shadowed in the scan stays blurry in the conditioning. The model doesn't paint features the scan didn't see.
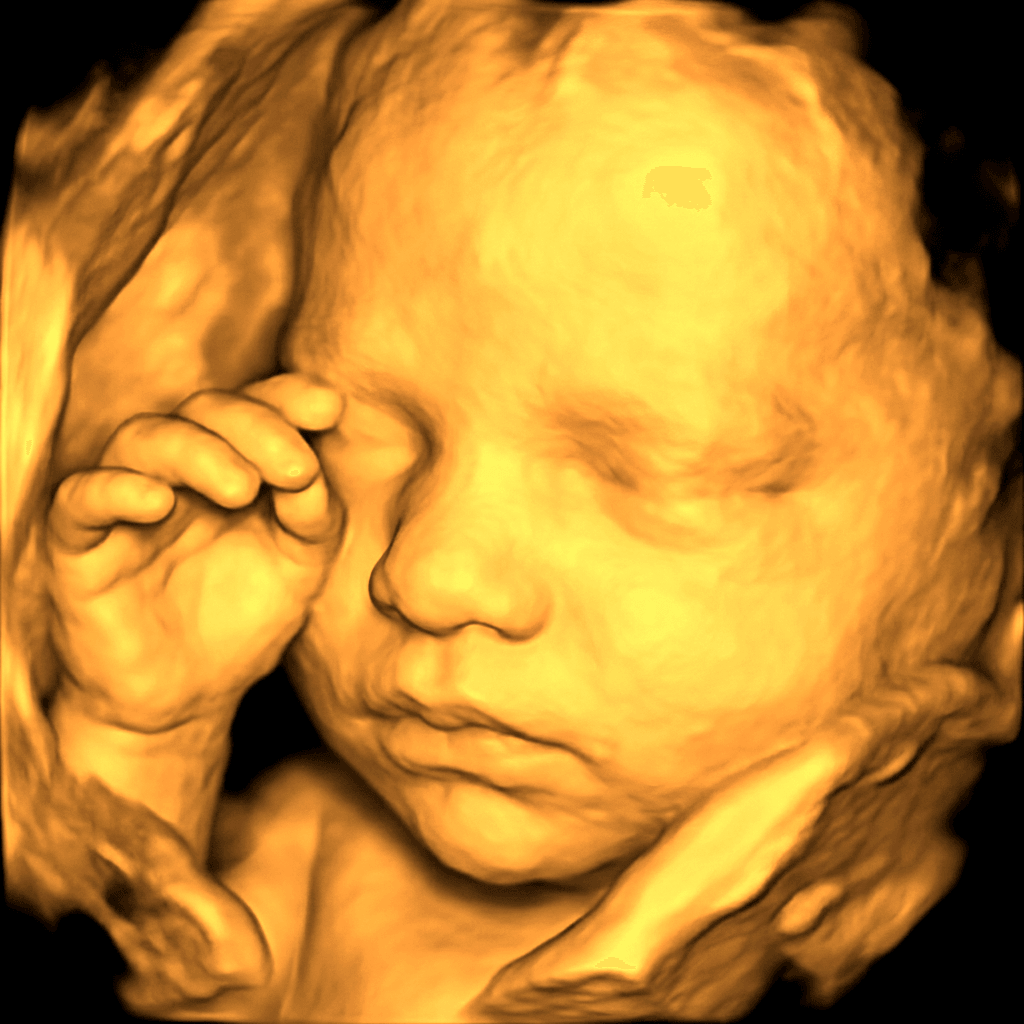
Vision pipeline · landmark anchors
The vision stage extracts only signals it can verify on the mesh. Everything below survives into the renderer; everything above the dotted line gets ignored so the model has nothing to hallucinate from.
This is why “the model can't paint what the scan didn't see” — half its inputs are explicitly discarded before rendering starts.
What happens between the upload button and the delivery email. Runtime estimates are rolling averages from production traffic — actual values fluctuate with GPU queue depth.
Sonographer uploads the same 3D/4D still she'd hand to the parent. We accept JPG / PNG / MP4 from any modern scanner — GE Voluson, Samsung HERA, Mindray DC-80, Philips EPIQ. No driver, no plugin, no scanner integration.
Our computer-vision pipeline analyses the 3D mesh: surface normals, facial landmark anchors (nose, eye orbits, chin curvature), lighting direction, mesh occlusions. These structural cues become the conditioning signal for the rendering model — they constrain pose, scale, and approximate proportion. The pipeline doesn't infer features it can't see.
Structural cues + studio's brand tokens + a curated reference embedding (drawn from a corpus of photographed newborns, parents-consented) get composed into the prompt + ControlNet inputs. This is where the model learns 'paint a newborn at the pose and proportion the scan dictates, in the visual style of a real-life portrait.'
A diffusion model — fine-tuned on a custom newborn-portrait corpus, not a stock SDXL fork — generates 5 candidate frames in parallel. Our scoring head picks the highest-fidelity-to-conditioning frame as the primary, holds the other 4 as alternates if the studio wants to regenerate. Average end-to-end stays under 3 minutes because most steps run concurrently.
Cobranded (Growth) or full white-label (Studio) overlay applied — frame, logo, color. Every output gets the mandatory "Artistic interpretation · Not a medical prediction" tag baked into both the image metadata and the delivery gallery copy. This isn't a UI toggle the studio can remove.
Branded gallery URL ships to mom via email + SMS. She forwards to grandparents, posts to Instagram, prints the favorite. Every share carries the studio's brand and the artistic-interpretation tag.
3D ultrasound + newborn portraiture has failure modes that off-the-shelf image AI hits hard. Here's what we had to solve, and how.
Real scans are full of acoustic shadow, partial occlusion, and surface artifacts the diffusion model would otherwise hallucinate into real features. The vision stage explicitly masks low-confidence regions and tells the renderer "don't paint here."
Out-of-the-box SDXL paints adults if you ask for "a baby." Our fine-tune corpus and conditioning prompts enforce neonatal proportion (eye-to-skull ratio, cheek fat, ear placement) — and reject any output that drifts toward adult features.
Ethnicity / skin tone is parent-supplied at upload — not inferred from the scan (the scan can't see it anyway). The conditioning prompt incorporates this explicitly, which avoids the common AI failure of defaulting to a single ethnicity.
Studios need consistent output across sessions. Our scoring head + seed pinning let the studio re-generate with adjusted style without losing the structural conditioning. Same scan + same brand tokens → similar but never identical output.
Studios sometimes assume more capability than the system actually has. Here's what the pipeline explicitly does NOT do — so you can frame it correctly to parents.
The output is an artistic interpretation in the visual style of a newborn portrait. It is not a biometric prediction. Two different scans of the same baby will produce two different portraits.
Nothing in the pipeline detects, diagnoses, screens for, or flags fetal anomalies. Every output is labeled non-diagnostic. Clinical questions belong with the parent's OB/GYN.
Customer scans uploaded through the studio dashboard are processed and deleted on a 90-day retention cycle. They never enter the training corpus for our or any third-party model.
TLS 1.3 + AES-256. Scans live in a private storage bucket; only the rendering pipeline has read access.
Scan inputs deleted on a 90-day rolling window. Generated portraits stay in the studio's dashboard until the studio deletes them.
Customer scans don't enter our training corpus. The reference embeddings the model uses are sourced separately, with parent consent.
Pilot is $39 for the month — enough deliveries to ship the workflow end-to-end and decide if the output quality earns its place in your packages. Full refund within 7 days if it doesn't.